Stand: 2011-05-11
In diesem Dokument erläutern wir das Informationsmodells "Medienverwaltung". Es liegt als Teil des Demonstrationsbeispiels "Medienverwaltung" der Auslieferung von Y.A.S. bei.
In einem ersten Abschnitt gehen wir zunächst auf den besonderen Zweck dieses Demonstrationsbeispiels ein, der Auswirkungen auf die Gestaltung und den Inhalt des Informationsmodells hat. Sodann spezifizieren wir im zweiten Abschnitt die fachliche Aufgabenstellung mit einer Schilderung des zu modellierenden Gegenstandsbereichs. In dem sich anschließenden eigentlichen Erläuterungsteil befassen wir uns zunächst mit der Festlegung der zu modellierenden Objekte und ihren Beziehungen, welche für die Modellierung des Gegenstandsbereichs durch Klassen und entsprechende Beziehungen strukturell bestimmend sind. Darauf folgend beschreiben wir die einzelnen Eigenschaften der Objekte durch Attribute an den Klassen und diskutieren dabei die Wahl der Datentypen für diese Attribute. Die Modellerläuterung beschließen wir mit der Angabe der anzeigebezogenen Zusatzkonfigurationen für Klassen und Attribute, d. h. deren Anzeigenamen, soweit sie vom Definitionsnamen abweichend gewählt sind. Außerdem erläutern wir die gewählten Bildungsregeln für Anzeigenamen von Instanzen und die Kriterien zur Erzielung einer geeigneten Sortierreihenfolge bei der Anzeige von Instanzmengen.
Zu dem Informationsmodell "Medienverwaltung" existiert ein Klassendiagramm in UML-Notation (Unified Modelling Language), das wir begleitend zu den einzelnen Abschnitten der Erläuterung in entsprechenden Ausschnitten zeigen und abschließend in vollem Umfang abbilden. Das Klassendiagramm wurde mit dem UML-Modellierungswerkzeug Umbrello erstellt, da Y.A.S. derzeit keine graphische Modellierung unterstützt. Weil Umbrello bzw. die UML nicht alle Modellierungskonstrukte von Y.A.S. abdecken, gehen wir im abschließenden Abschnitt kurz auf das Thema Werkzeugunterstützung für die graphische Visualisierung von Informationsmodellen ein und geben an, in welcher Weise das gezeigte Klassendiagramm vom Informationsmodell "Medienverwaltung" abweicht.
Das hier behandelte Informationsmodell "Medienverwaltung" stellt ein fiktives Demonstrationsbeispiel dar. Es wurde vorrangig zu dem Zweck erstellt, den Aufbau und die Verwendung eines Informationsmodells mit Y.A.S. anhand eines einfachen und eingängigen Beispiels zu demonstrieren. Als Gegenstandsbereich haben wir den Bereich Medienverwaltung gewählt, weil dieser Bereich den weitaus meisten Lesern aus ihrem Alltag bekannt sein dürfte, unabhängig davon, ob und wie sie selbst Mediensammlungen bereits computergestützt oder mit anderen Mitteln verwalten. Um die Übersichtlichkeit zu wahren, beschränken wir uns auf die Verwaltung von Büchern und Zeitschriften als Medientypen. Somit sollte es für jeden Interessierten leicht möglich sein, die fachlichen und technischen Zusammenhänge des Demonstrationsbeispiels nachzuvollziehen und ggf. die ersten eigenen Schritte beim Ausprobieren von Y.A.S. anhand der mitgelieferten Beispieldatendatei zu machen.
Wie jedes Modell, so bildet das Informationsmodell "Medienverwaltung" einen bestimmten Gegenstandsbereich bezüglich bestimmter interessierender Aspekte ab. Die gewählten Aspekte hängen unter anderem vom beabsichtigten Verwendungszweck des Modells ab. Bei Y.A.S. werden Informationsmodelle zu dem Zweck erstellt, die interessierenden Objekte, Eigenschaften und Zusammenhänge des Gegenstandsbereichs von ihrer Art her datentechnisch zu beschreiben. Diese Beschreibung dient als Grundlage, um mit Y.A.S. daraus ein Datenschema und weitere Konfigurationen abzuleiten und entsprechende Daten zu konkreten Objekten des Gegenstandsbereichs erfassen, speichern, laden, abfragen, anzeigen und bearbeiten zu können.
Ein Hauptaugenmerk bei der Gestaltung des Beispiels lag auf der Demonstration aller von Y.A.S. zur Verfügung gestellten Modellierungskonstrukte. Inbesondere war es das Ziel der Modellerstellung, jedes Modellierungskonstrukt mindestens ein Mal anzuwenden, um dem Leser einen vollständigen Überblick über die Möglichkeiten der Informationsmodellierung mit Y.A.S. zu geben. Die sachliche Angemessenheit bei der Verwendung der Modellierungskonstrukte mag dabei im Einzelfall durchaus zu hinterfragen sein. Die Frage nach alternativen und eventuell besseren Modellierungsvarianten wird an gegebener Stelle in den nachfolgenden Erläuterungen mit diskutiert. Dabei geben wir auch Lösungsvarianten mit solchen Modellierungskonstrukten an, die derzeit in Y.A.S. noch nicht realisiert sind, deren Anwendung aber bei entsprechender Erweiterung von Y.A.S. denkbar wäre.
Bei der Durchsicht des Informationsmodells "Medienverwaltung" und dieser Erläuterung mag dem einen oder anderen Leser die Gestaltung des Modells fragwürdig erscheinen, sei es, weil er in der Darstellung des Gegenstandsbereichs sachliche Fehler erkennt, sei es, weil er den Gegenstandsbereich bei Verwendung der verfügbaren Modellierungskonstrukte anders abbilden würde, sei es, weil ihm die Verwendung von Y.A.S. als Werkzeug zur Datenmodellierung und Datenhaltung für den vorliegenden Gegenstandsbereich fraglich erscheint. Als fiktives Demonstrationsbeispiel erhebt das Informationsmodell "Medienverwaltung" keinen Anspruch auf sachliche Richtigkeit, angemessene Darstellung und praktische Eignung für eine reale Verwendung. Dem Leser steht es frei, das Informationsmodell nach seinen eigenen Vorstellungen anzupassen und dann ggf. mit selbst erfassten Beispieldaten zu erproben.
Gegeben sei eine private Bibliothek, in der ihr Besitzer seine Bücher und Zeitschriften aufbewahrt. Die Bibliothek sei mit einem Regalsystem bestehend aus mehreren Regalen ausgestattet, bei dem die einzelnen Regale eine variable Anzahl von Regalebenen umfassen und jede Regalebene eines Regals durch optionale Fachteiler in mehrere Regalfächer unterteilt werden kann. Jedes Buch und jede Zeitschrift werden gewöhnlich in einem bestimmten Fach des Regalsystems aufbewahrt, wo sie bei Bedarf schnell aufgefunden werden können und in das sie nach einer Benutzung wieder zurückgestellt werden. Von Zeit zu Zeit leiht der Besitzer der Bibliothek Bücher und Zeitschriften für einen bestimmten Zeitraum auch an andere, ihm bekannte Personen aus.
Inhaltlich soll das Informationsmodell beschreiben, mit welchen bibliographischen Angaben Bücher und Zeitschriften erfasst werden, welche weiteren Informationen bzgl. Aufbewahrungsort, aktuelle Ausleihen und Entleiher zu verzeichnen sind und wie alle diese Informationen datentechnisch repräsentiert werden sollen. Im Einzelnen sind dazu folgende Angaben zu berücksichtigen:
Bücher werden mit ihrem Titel, dem Erscheinungsjahr, den Namen ihrer Autoren und/oder Herausgeber, dem Preis, dem Klappentext, der zugeordneten internationalen Standardbuchnummer (ISBN) im alten 10-stelligen und/oder im neuen 13-stelligen Format sowie einem vom Besitzer der Bibliothek vergebenen Ordnungsmerkmal erfasst. Außerdem soll verzeichnet werden, ob es sich bei einem Buch entweder um ein literarisches Buch, ein Sachbuch, ein Kinderbuch, ein Jugendbuch, ein Lexikon, ein Liederbuch, ein Schulbuch, ein Lehrbuch oder ein wissenschaftliches Buch handelt (keine Mehrfachangabe).
Zeitschriften werden mit ihrem Titel, der Ausgabenummer, dem Erscheinungsjahr, der Jahrgangsnummer, dem Erscheinungsdatum, dem Preis, der zugeordneten internationalen Standardseriennummer (ISSN) sowie einem vom Besitzer der Bibliothek vergebenen Ordnungsmerkmal erfasst.
Regale, Regalebenen und Regalfächer sollen nach einem geeigneten, hierarchisch aufgebauten System mit Nummern identifiziert werden können.
Jeder Entleiher wird mit Nachname, Vorname, Geburtsdatum, Geschlecht, Anschrift, E-Mail-Adresse, Festnetz- und Mobiltelefonnummer sowie einer Liste seiner Lieblingsautoren erfasst. Zusätzlich soll zu jedem Entleiher ein freier Bemerkungstext erfasst werden können, und es soll angegeben werden können, ob die Person als Entleiher besonders vertrauenswürdig ist. Außerdem sollen zum Entleiher bestimmte (z. B. häufig ausgeliehene) Bücher als Lieblingsbücher vermerkt werden können, nicht jedoch Zeitschriften.
Zu aktuellen Buchausleihen soll ein vorgesehenes Rückgabedatum erfasst werden.
Entsprechend dem Ziel des Informationsmodells "Medienverwaltung", die Anwendung der von Y.A.S. angebotenen Modellierungskonstrukte zu demonstrieren, wird nachfolgend erläutert, welche Konstrukte für die Modellierung der jeweiligen Sachverhalte des Gegenstandsbereichs gewählt wurden.
Wir gehen dabei vom Allgemeinen zum Besonderen vor. Wir beginnen mit der Festlegung der Klassen und der Bestimmung der Beziehungen zwischen ihnen, die beide die logische Modellstruktur bestimmen. Danach gehen wir auf die Festlegung der Attribute und die Wahl der ihnen zugeordneten Datentypen ein. Abschließend geben wir die von den Definitionsnamen der Klassen und Attribute abweichenden Anzeigenamen sowie die im Modell hinterlegten Bildungsregeln für die Anzeigenamen und Sortierkriterien für Instanzen an.
Inhaltlich soll das Informationsmodell beschreiben, wie eine Anzahl von Büchern und Zeitschriften mit ihren bibliographischen Angaben zu verwalten sind. Dabei soll für jedes dieser Bücher und jede dieser Zeitschriften angegeben werden können, welches hierfür gewöhnlich der Aufbewahrungort in den Fächern eines Regalsystems ist. Desweiteren soll verwaltet werden können, welche Person das Buch bzw. die Zeitschrift ggf. aktuell ausgeliehen hat.
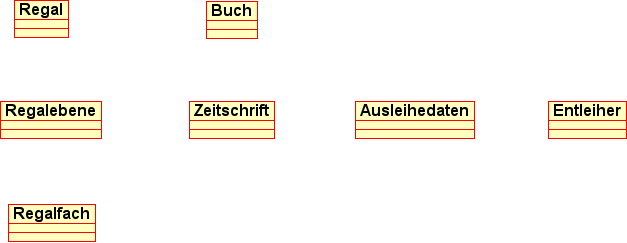
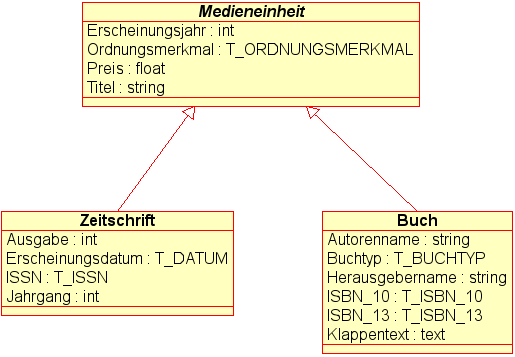
Ein erster Modellierungsschritt ergibt Kandidaten für Entitäten, die als Klassen zu modellieren sind (vgl. die nachfolgende Abbildung).
Wir untersuchen nun, welche Beziehungen zwischen diesen Klassen im Sinne des zu modellierenden Gegenstandsbereichs bestehen und von welcher Art diese Beziehungen sind. Ggf. müssen wir dabei die Art der Klassen an die erkannten Beziehungen anpassen. Evtl. müssen wir auch weitere Klassen einführen oder können nicht mehr benötigte Klassen entfernen. Auch betrachten wir zu diesem Zeitpunkt schon grob die voraussichtlichen Eigenschaftsmengen der Klassen, um zu einer sinnvollen Modellierung zu gelangen. Kurz gesagt überprüfen wir noch einmal die Existenzberechtigung und Sinnhaftigkeit der Klassen anhand ihrer strukturellen Funktion in unserem Modell. Bei der Untersuchung konzentrieren wir uns jeweils auf unterschiedliche Teilbereiche des Modells, die in den nachfolgenden Abschnitten behandelt werden.
Bücher und Zeitschriften weisen sowohl gemeinsame Eigenschaften
(z. B. Titel, Erscheinungsjahr, Aufbewahrungsort) wie auch
unterschiedliche Eigenschaften (z. B. Autor und ISBN-Nummer bei Büchern,
Ausgabenummer und ISSN-Nummer bei Zeitschriften) auf.
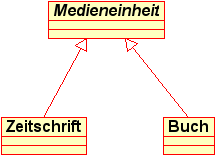
Daher werden im Informationsmodell Bücher
und Zeitschriften als zwei verschiedene Klassen
Buch und Zeitschrift repräsentiert, die
von einer gemeinsamen Basisklasse Medieneinheit
erben.
An der Basisklasse Medieneinheit werden die Attribute für
gemeinsame Eigenschaften von Büchern und Zeitschriften definiert.
Sie ist als abstrakte, d. h. nicht direkt instanzierbare Klasse
gekennzeichnet; denn von ihr selbst sollen keine Datenobjekte angelegt
werden können, sondern nur von ihren konkreten, d. h. instanzierbaren
Unterklassen.
Um den Standort eines Buches in einem Regalsystem beschreiben zu können, wird eine logische Zerlegung (Dekomposition) des Regalsystems in einzelne Regale vorgenommen. Jedes Regal kann eine nicht vorbestimmte Anzahl von Regalebenen umfassen, und jede Regalebene kann z. B. durch Fachteiler in eine ebenfalls nicht vorbestimmte Anzahl von Regalfächern weiter unterteilt sein. Für die Identifizierung der Regale, Regalebenen und Regalfächer wird eine Numerierung der Objekte auf jeder dieser logischen Dekompositionsebenen vorgenommen. Die Numerierung soll relativ zum jeweils übergeordneten Objekt der nächsthöheren Dekompositionsebene erfolgen, d. h. es kann in jedem Regal die Regalebenen 1, 2, 3, ... und in jeder Regalebene die Regalfächer 1, 2, 3, ... geben. Ein Regalfach ist damit durch das Tripel aus Regalnummer, Ebenennummer und Fachnummer eindeutig identifizierbar. Ob dem gewählten Numerierungsschema darüber hinaus noch eine fachliche Semantik zugeordnet wird, soll für dieses Beispiel zunächst offen bleiben. Eine Entscheidung dieser Frage würde im konkreten Anwendungsfall von den sachlichen Gegebenheiten und dem Verwendungszweck des Informationsmodells abhängen.
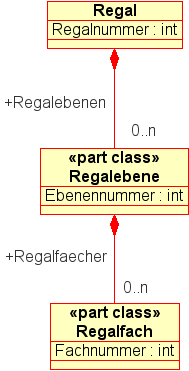
Die Repräsentation des Regalsystems bestehend aus Regalen,
Regalebenen und Regalfächern erfolgt explizit mittels entsprechender
Datenobjekte auf den einzelnen Dekompositionsebenen.
Dazu enthält das Informationsmodell die Klassen Regal,
Regalebene und Regalfach zusammen mit den beiden
erwähnten Teil-Ganzes-Beziehungen (Kompositionsbeziehungen)
zwischen diesen Klassen.
Die Kompositionsbeziehung Regalebenen von der Klasse
Regal zur Klasse Regalebene modelliert,
dass ein Regal aus mehreren Regalebenen bestehen kann.
Die Kompositionsbeziehung Regalfaecher von der Klasse
Regalebene zur Klasse Regalfach modelliert,
dass eine Regalebene aus mehreren Regalfächern bestehen kann.
Durch die explizite Repräsentation des Regalsystems durch entsprechende
Instanzen kommt einem Regalfach in einer konkreten Datensammlung somit
nicht nur ein bestimmtes eindeutig identifizierendes Tripel aus
Regalnummer, Ebenennummer und Fachnummer zu,
sondern auch eine datentechnische Objektidentität im Rahmen der
Objektdatenhaltung, so dass von anderer Stelle in der Objektdatenhaltung
direkt auf eine Instanz der Klasse Regalfach verwiesen werden
kann.
Dies kann als Verzeigerung zwischen Instanzen mittels Objektreferenzen
aufgefasst werden. Bei der manuellen oder maschinellen Datenauswertung
besteht damit die einfache Möglichkeit, ohne besondere Suchoperationen
im Datenbestand entlang von Objektreferenzen von Instanz zu Instanz
zu navigieren. Die technische Darstellung der datentechnischen
Objektidentität und damit auch die technische Umsetzung von
Objektreferenzen ist ein Implementierungsdetail von Y.A.S. und für die
Informationsmodellierung nicht relevant.
Eine weitere allgemeine Bemerkung zur Komposition betrifft die Dauerhaftigkeit einmal erzeugter Kompositionsbeziehungen zwischen Instanzen und die daraus erwachsenden Abhängigkeiten zum Lebenszyklus, genauer zur Erzeugung und Löschung der beteiligten Instanzen. Allgemein gesprochen muss die Kompositionsbeziehung zwischen einer besitzenden Instanz und einer Teil-Instanz während der gesamten Lebensdauer der Teil-Instanz unverändert existieren. Dies bedeutet, dass
Als Teil-Klasse einer Kompositionsbeziehung kann grundsätzlich jede konkrete Klasse eines Informationsmodells verwendet werden. Die Existenz einer Kompositionsbeziehung schließt also zunächst nicht aus, das die als Teil-Klasse verwendete Klasse nicht auch unabhängig von einer besitzenden Instanz instanziert werden kann. Ob eine Instanz also eine Teil-Instanz oder eine gewöhnliche Instanz ist, hängt ausschließlich davon ab, ob die betreffende Instanz zusammen mit einer konkreten Kompositionsbeziehung zu einer besitzenden Instanz angelegt wurde oder nicht. Soll eine unabhängige Instanzierung einer als Teil-Klasse verwendeten Klasse ausgeschlossen werden, so ist die Teil-Klasse im Informationsmodell mit der entsprechenden Klassenart anzulegen (part class statt ordinary class).
Kompositionsbeziehungen ermöglich die hierarchische Navigation in einer entsprechend strukturierten Instanzmenge. Um auch allgemeine Beziehungen (auch als Referenzen bzw. Assoziationen bezeichnet) zwischen Objekten darstellen zu können, gibt es in Y.A.S. derzeit nur den als Referenz bezeichneten Beziehungstyp. Eine Referenz modelliert einseitige Instanzbeziehungen zwischen jeweils einem verweisenden Datenelement und einer Instanz, auf die verwiesen werden soll. Das verweisende Datenelement kann dabei selbst eine Instanz sein, muss es jedoch theoretisch und auch praktisch nicht sein. Die verwiesene Instanz wird auch als Ziel-Instanz bezeichnet. Referenzen sind in Y.A.S. typisiert. Das bedeutet, dass im Informationsmodell zu der Referenz angegeben werden muss, aus welcher Klasse die zulässigen Ziel-Instanzen kommen. Diese Klasse wird als Ziel-Klasse der Referenz bezeichnet. Referenzen werden in einem Informationsmodell zumeist als Attribute von Klassen definiert und können dann auch graphisch mit der UML als Beziehungen in einem Klassendiagramm visualisiert werden. Y.A.S. ermöglicht darüber hinaus, Referenzen als Elementtyp beliebiger, auch verschachtelter Containertypen wie Mengen, Listen und Zuordnungen zu verwenden. Solche Beziehungen können nicht in jedem Fall einfach in Klassendiagrammen graphisch dargestellt werden und bedürfen zumindestens ergänzender Angaben im Informationsmodell (z. B. der Spezifikation des verwendeten Containertyps). Assoziative Beziehungen zwischen Instanzen sind im Unterschied zu Kompositionsbeziehungen während der Lebenszeit der beteiligten Instanzen in einer Datensammlung beliebig änderbar.
Eine Anforderung an die Medienverwaltung besagt, dass die aktuellen Ausleihen von Medieneinheiten mit den jeweiligen Entleihern zu erfassen sind.
Als Entleiher kommen ausschließlich natürliche Personen
in Frage, die wir mit der Klasse Entleiher modellieren.
Wir verzichten aus pragmatischen Gründen auf eine allgemeinere
Modellierung, wie sie z. B. mit einer Klasse Person,
ggf. auch als Basisklasse der Klasse Entleiher denkbar
wäre. Ein solcher Ansatz wäre durch Überlegungen
z. B. zur Wiederverwendung der allgemeinen Eigenschaften einer Person
zu motivieren und gegen andere Lösungsansätze wie z. B.
die Verwendung des Delegations-Musters abzuwägen.
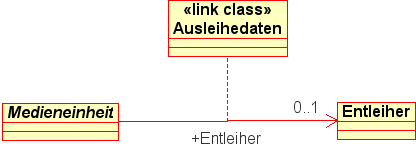
Die aktuelle Ausleihe einer Medieneinheit durch einen Entleiher können wir als Beziehung zwischen einer Medieneinheit und ihrem derzeitigen Entleiher auffassen. Eine Medieneinheit kann zu einem bestimmten Zeitpunkt höchstens durch einen Entleiher ausgeliehen sein. Umgekehrt kann ein Entleiher zu einem Zeitpunkt beliebig viele Medieneinheiten ausgeliehen haben. Für jede Ausleihe einer Medieneinheit soll vermerkt werden, bis zu welchem Datum die Medieneinheit durch den Entleiher zurückzugeben ist.
Eine solche Beziehung, der beschreibende Eigenschaften
zugeordnet sind, modellieren wir mit
einer attributierten Referenz. (Assoziationen sind in Y.A.S. noch nicht
implementiert.) Im Fall der Ausleihe von Medieneinheiten durch Entleiher
berücksichtigen wir die zuvor angegebene Kardinalitätsbedingung,
im Informationsmodell, indem wir im Modell eine einzelwertige
Referenz von der Klasse Medieneinheit zur Klasse
Entleiher verwenden.
Das entsprechende Referenzattribut an der Ausgangsklasse
Medieneinheit heißt Entleiher
Die Eigenschaften, die die Beziehung näher beschreiben, werden als
Attribute der Verbindungsklasse (link class)
Ausleihedaten modelliert. Die Verbindungsklasse
ist der Referenz Entleiher fest zugeordnet.
Als Beispiel für eine listenwertige Referenzbeziehung
enthält das Informationsmodell "Medienverwaltung"
an der Klasse Entleiher das Referenzattribut
Lieblingsbuecher. Dieses Attribut gibt für jeden
Entleiher seine Lieblingsbücher an, die datentechnisch
als Menge von Referenzen auf die entsprechenden Instanzen der Ziel-Klasse
Buch repräsentiert werden.
Diesem Referenzattribut ist keine Link-Klasse zugeordnete, da
zu den Referenzen keine weiteren Eigenschaften angegeben werden.
In diesem Zusammenhang seien noch einige Anmerkungen zum hier verwendeten Kollektionstyp Menge gestattet: Im Gegensatz zum Kollektionstyp Liste können die Elemente einer Menge nicht in einer vom Benutzer vorgegebenen Reihenfolge angeordnet werden. Außerdem können Elemente per Definition nicht mehrfach in einer Menge auftauchen. Beide Einschränkungen sind in diesem Fall sachlich akzeptabel. Soll es dem Benutzer ermöglicht werden, die Reihenfolge der Lieblingsbücher vorzugeben, so wäre der Kollektionstyp Liste zu verwenden. Hierbei müsste dann im Informationsmodell explizit vermerkt werden, dass jedes Element nur einmal in der Liste vorkommen darf. Auch bei einer Menge muss die Reihenfolge der Elemente beim Anzeigen bzw. Durchlaufen nicht zufällig sein; denn eine gute Implementierung des Kollektionstyps Menge zeichnet sich dadurch aus, dass bei einer Aufzählung bzw. Iteration die Elemente der Menge gemäß einer Standardsortierung angezeigt bzw. durchlaufen werden können.
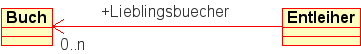
Der letzte hier zu behandelnde Zusammenhang zwischen Objekten des zu modellierenden Gegenstandsbereichs ist der Aufbewahrungsort von Büchern und Zeitschriften. Hier besteht eine Beziehung zwischen Büchern und Zeitschriften auf der einen Seite und den Fächern des Regalsystems auf der anderen Seite. Je nach Anwendungsfall, für den die Beziehung ausgewertet werden soll, kann einmal die Frage nach dem Standort eines Buches oder einer Zeitschrift gestellt werden, ein anderes Mal mag die Frage interessieren, welche Bücher und Zeitschriften in einem bestimmten Regalfach eingestellt sind. Modelltechnisch bezeichnen wir diese Art von Beziehungen, die in beide Richtungen ausgewertet werden können sollen, als Assoziationen. Derzeit unterstützt Y.A.S. noch nicht die direkte Modellierung von Assoziationen. Wir behelfen uns hier vorerst mit dem Umweg über die Modellierung zweier entgegengesetzter, quasi spiegelbildlich zu verwendender einseitiger Referenzen.
Das Referenzattribut Standort weist jeder Instanz der
abstrakten Oberklasse Medieneinheit genau eine Instanz
der Klasse Regalfach zu.
Das mengenwertige Referenzattribut eingestellteMedieneinheiten
weist jeder Instanz der Klasse Regalfach eine Menge
von Instanzen der abstrakten Oberklasse Medieneinheit zu.
Nachteilig an dieser Modellierung ist, dass mit der Darstellung der sachlich gegebenen Assoziationsbeziehung durch zwei spiegelbildlich zu verwendende Referenzattribute ein sachlicher Zusammenhang auf zwei datentechnisch unabhänge Instanzbeziehungen abgebildet wird. Diese Modellierung erzeugt damit eine Problematik hinsichtlich der konsistenten Belegung beider Attribute, bei der der Anwender mangels Werkzeugunterstützung selbst den konsistenten Datenzustand zu gewährleisten hat.

In diesem Abschnitt erläutern wir für die einzelnen Klassen die nicht-referenziellen Attribute, die die lokalen Eigenschaften der Objekte beschreiben, und geben dazu die verwendeten Datentypen an. Fallweise weisen wir auch auf alternative Modellierungsmöglichkeiten hin, die zum Teil über die derzeit in Y.A.S. implementierten Modellierungskonstrukte hinausgehen und entsprechend noch nicht umgesetzt werden können.
Eine Übersicht über die Verwendungsstellen der verschiedenen Datentypen gibt die folgende Tabelle, bevor wir uns mit den einzelnen Klassen und deren Attributen befassen.
| Datentyp | Verwendung in Klasse / bei Attribut |
|---|---|
| boolean | Entleiher / vertrauenswuerdig |
| enum (anonym) | Entleiher / Geschlecht |
| float | Medieneinheit / Preis |
| int | Medieneinheit / Erscheinungsjahr Regal / Regalnummer Regalebene / Ebenennummer Regalfach / Fachnummer Zeitschrift / Ausgabe Zeitschrift / Jahrgang |
| list<...> | Entleiher / Lieblingsautoren |
| map<...> | Entleiher / Fremdsprachen |
| string | Buch / Autorenname Buch / Herausgebername Entleiher / Anschrift Entleiher / Geburtsdatum Entleiher / Nachname Entleiher / Vorname Medieneinheit / Titel |
| text (string<multiline>) | Buch / Klappentext Entleiher / Bemerkung |
Die nachfolgend beschriebenen Attribute
Erscheinungsjahr, Ordnungsmerkmal,
Preis und Titel sind sowohl für
die Angabe der bibliographischen Daten von Bücher als auch von
Zeitschriften relevant.
Sie werden daher an der abstrakten Basisklasse Medieneinheit
definiert und gelten damit gleichermaßen für die davon
abgeleiteten Unterklassen Buch und Zeitschrift mit.
Das Attribut Erscheinungsjahr enthält das
Erscheinungsjahr der Medieneinheit als Ganzzahl
(Wert vom Datentyp int).
Der Wertebereich des Attributs ist aus Plausibilitätsgründen
begrenzt auf Werte von 1700 bis 2100. Die Wertebereichsgrenzen
sind im Klassendiagramm nicht dargestellt.
Das Attribut Ordnungsmerkmal enthält einen
über alle Medieneinheiten eindeutigen Bezeichner zu
Verwaltungszwecken als einfache Zeichenkette. Das Attribut
verweist diesbezüglich auf den Typ-Alias
T_ORDNUNGSMERKMAL, der lokal in der Klasse
Medieneinheit definiert ist.
Das Attribut Preis enthält den Beschaffungspreis der
Medieneinheit als Gleitkommazahl in der Einheit Euro (Wert vom Datentyp
float).
Der Wertebereich des Attributs ist aus Plausibilitätsgründen
begrenzt auf Werte von 0.01 bis 199.99. Die Wertebereichsgrenzen
sind im Klassendiagramm nicht dargestellt.
Eine alternative Modellierungsmöglichkeit, die in Y.A.S. aber noch
nicht realisiert ist, bestände in der Verwendung eines eingebauten
Datentyps für Währungsbeträge, der die explizite
Angabe der Währungseinheit vorsähe.
Das Attribut Titel enthält den Titel der
Medieneinheit als einfache Zeichenkette (ohne Zeilenumbrüche;
Wert vom Datentyp string).
Für die Klasse Buch sind zusätzlich zu den
ererbten Attributen der Klasse Medieneinheit die folgenden
Attribute definiert:
Die Attribute Autorenname und Herausgebername
enthalten den Namen des Buchautors bzw. den Namen des Herausgebers
des Buches als einfache Zeichenkette (Wert von Datentyp string).
Gibt es zu dem Buch mehr als einen Autor bzw. Herausgeber, so sollen
die Namen aller Autoren bzw. Herausgeber, durch geeignete Trennzeichen
voneinander abgesetzt, hintereinander geschrieben werden. Für die
Schreibung der einzelnen Namen (Reihenfolge der Namen, Anordnung
von Vor- und Nachname, bei umgekehrter Anordnung ggf. durch Komma getrennt,
Verwendung von Vornamens-Initialien) werden keine Vorgaben gemacht.
Alternativ zur gewählten Lösung könnte eine Reihe
anderer Modellierungsvarianten in Betracht kommen, die eine Liste von
Einträgen für die Autoren- bzw. Herausgebernamen verwenden und
sich in der Repräsentation der einzelnen Namen unterscheiden:
Die erste Variante verwendet für die einzelnen Namen einfache
Zeichenkettendarstellungen als Listeneinträge, wobei die Schreibung
der einzelnen Namen wie oben dem Anwender obliegt.
Die zweite Variante verwendet für die einzelnen Namen strukturierte
Werte, so dass die Namensbestandteile einzeln repräsentiert
werden können, z. B. durch eine Liste von einfachen Zeichenketten
für den oder die Vornamen und eine einfache Zeichenkette für
den Nachnamen. Diese Variante hätte den Vorteil, dass auf die
einzelnen Namensbestandteile von Autoren bwz. Herausgebern direkt
zugegriffen werden kann.
Als dritte Variante wäre denkbar, statt der
ausgeschriebenen Namen lediglich Referenzen auf Instanzen einer
noch in das Informationsmodell aufzunehmenden Klasse für Autoren und
Herausgeber zu speichern. Diese Variante hätte den Vorteil, dass
ggf. durch Namensgleichheit verursachte Uneindeutigkeiten bei der
namensbasierten Referenzierung von Autoren und Herausgebern datentechnisch
ausgeschlossen wären und dass die Frage der Repräsentation
der Autoren- bzw. Herausgebernamen an zentraler Stelle, nämlich in der
vorgenannten Klasse gebündelt wäre.
Die vermiedene Mehrdeutigkeit einer namensbasierten Referenzierung
von Autoren bzw. Herausgebern kann aber auch als Nachteil gewertet werden,
da der Benutzer gezwungen ist, eventuelle Mehrdeutigkeiten gleich bei der
Datenerfassung aufzulösen, obwohl er dazu vielleicht faktisch nicht
in der Lage ist.
Das Attribut Buchtyp enthält eine Kategorisierung,
um welche Art von Buch es sich handelt. Die zutreffende Kategorie wird
durch den Wert eines Aufzählungstyps repräsentiert, der hier
durch den separat definierten Aufzählungstyp
T_BUCHTYP gegeben ist.
Die Attribute ISBN_10 und ISBN_13 enthalten
die alte 10-stellige bzw. die neue 13-stellige internationale
Standardbuchnummer (International Standard Book Number),
die den Buchtitel z. B. für Bestellvorgänge im Buchhandel
eindeutig identifiziert.
Für beide Attribute ist im Informationsmodell jeweils ein
eigener benutzerdefinierter Datentyp / Typ-Alias
T_ISBN_10 bzw. T_ISBN_13 definiert.
Beide basieren auf dem Datentyp string für
einfache Zeichenketten ohne Zeilenumbrüche und regeln neben
der Länge auch das Format zulässiger Werte, die hier
ohne jegliche Trennzeichen angegeben werden müssen.
Als alternative Modellierungsmöglichkeiten kommen eine
aufwändigere Formatspezifikation zur Berücksichtigung der
Trennzeichen zwischen den 4 bzw. 5 Zifferngruppen der alten bzw. neuen
ISBN in Betracht sowie eine Repräsentation als eine einzige Ganzzahl
mit einer binären Länge von mindestens 34 bzw. 47 Bit.
Eine weitere, mit Y.A.S. derzeit allerdings noch nicht realisierbare
Möglichkeit besteht in der Verwendung eines benutzerdefinierten
Strukturtyps mit den jeweiligen Anteilen der ISBN als
Strukturelemente vom Typ string oder int:
Präfix (3-stellig; nur ISBN 13),
Gruppennummer (1- bis 3-stellig), Verlagsnummer, Titelnummer und
Prüfziffer (1-stellig).
Das Attribut Klappentext nimmt einen ggf. mehrzeiligen
Text auf, der als sogenannter Klappentext zumeist auf dem Einband
bzw. Umschlagrücken eines Buches steht und eine kurze
Beschreibung zum Inhalt und ggf. auch zu den Autoren des Buches
enthält.
Für die Klasse Zeitschrift sind zusätzlich zu den
ererbten Attributen der Klasse Medieneinheit die folgenden
Attribute definiert:
Das Attribut Ausgabe enthält die laufende Nummer
der Ausgabe innerhalb des zugehörigen Jahrgangs als ganzzahligen
Wert. Sie beginnt in der Regel in jedem Jahrgang wieder mit 1.
Das Attribut Erscheinungsdatum enthält die Angabe
des Datums nach internationaler Zeitrechnung, zu dem die Zeitschrift
erstmals im Handel erhältlich ist. Bzgl. des Datentyps
verweist das Attribut auf die separate Typdefinition T_DATUM,
die Datumsangaben in Form einfacher Zeichenketten ohne Zeilenumbrüche
vorsieht und per Formatdefinition regelt, wie im Allgemeinen eine
Datumsangabe auszusehen hat.
Als alternative Modellierungsmöglichkeiten kommt entweder die
Verwendung eines benutzerdefinierten Strukturtyps mit einer
Aufschlüsselung der elementaren Datums-Bestandteile (Jahr, Monat,
Tag) oder die Verwendung eines eingebauten Datentyps für
Datumsangaben in Frage. Beides ist in Y.A.S. noch nicht realisiert.
Das Attribut ISSN enthält
die 8-stellige internationale
Standardseriennummer (International Standard Serial Number),
die die Zeitschrift z. B. für Bestellvorgänge im Buchhandel
eindeutig identifiziert.
Für dieses Attribut ist im Informationsmodell ein
eigener benutzerdefinierter Datentyp bzw. Typ-Alias
T_ISSN definiert.
Er basiert auf dem Datentyp string für
einfache Zeichenketten ohne Zeilenumbrüche und regelt neben
der Länge auch das Format zulässiger Werte, die hier
entweder mit oder ohne Bindestrich als Trennzeichen zwischen der
ersten und der zweiten Gruppe von vier Ziffern angegeben werden
können.
Als alternative Modellierungsmöglichkeiten kommt eine
Repräsentation als eine einzige Ganzzahl
mit einer binären Länge von mindestens 27 Bit in Betracht.
Eine weitere, mit Y.A.S. derzeit allerdings noch nicht realisierbare
Möglichkeit besteht in der Verwendung eines benutzerdefinierten
Strukturtyps mit der eigentlichen 7-stelligen Nummer und der 1-stelligen
Prüfziffer der ISSN als
Strukturelemente vom Typ string oder int.
Das Attribut Jahrgang enthält die laufende Nummer
des Jahrgangs, zu dem die Zeitschriftenausgabe gehört, als
ganzzahligen Wert. Die Zählung beginnt in
der Regel mit 1 für den ersten Jahrgang der Zeitschrift.

Wie bereits oben im Zusammenhang mit den Kompositionsbeziehungen
erläutert, werden Regale, Regalebenen und Regalfächer
jeweils relativ zur übergeordneten Instanz auf der
nächsthöheren Dekompositionsebene
mit einer laufenden Nummer identifiziert. Hierzu dienen die Attribute
Regalnummer, Ebenennummer und
Fachnummer der jeweiligen Klasse. Im Informationsmodell
"Medienverwaltung" sind bei diesen Attributen die erlaubten Wertebereiche
durch die Angabe des jeweils kleinsten und größten
zulässigen Wertes näher spezifiziert. Dies ist sinnvoll,
um z. B. bei der Datenerfassung unplausible Angaben erkennen zu können.
Wertebereichsgrenzen werden im abgebildeten Klassendiagramm nicht dargestellt.
Sie sind nur in der entsprechenden Attributdefinition im
Informationsmodell "Medienverwaltung" spezifiziert, die man sich mit Y.A.S.
anzeigen lassen kann.

Das Attribut Anschrift enthält die Anschrift des Entleihers
als einfache Zeichenkette (ohne Zeilenumbrüche; Wert vom Datentyp
string).
Im Hinblick auf alternative Modellierungsmöglichkeiten könnte die
Anschrift auch in ihre elementaren Bestandteile wie Straße,
Hausnummer, Postleitzahl, Ort etc. zerlegt werden. Dabei böten sich
zwei konkrete Modellierungsvarianten an:
Eine Variante bestände darin, die einzelnen Adressbestandteile als
eigenständige Attribute der Klasse Entleiher darzustellen.
Bei der zweiten, mit Y.A.S. noch nicht darstellbaren Variante würde
für das Attribut Anschrift ein benutzerdefinierter
Strukturtyp (vergleichbar dem aus C/C++ bekannten struct oder dem
record in Pascal) definiert und verwendet, so dass strukturierte
Werte dargestellt und ihre einzelnen Bestandteile gezielt zugegriffen
werden könnten.
Das Attribut Bemerkung nimmt einen ggf. mehrzeiligen
Text mit Bemerkungen zum Entleiher auf.
Das Attribut Email enthält die E-Mail-Adresse des
Entleihers als einfache Zeichenkette. Da E-Mail-Adressen nach
einem bestimmten Muster aufgebaut sein müssen, wird zusätzlich
zum Datentyp string eine Formatangabe für E-Mail-Adressen
spezifiziert.
Somit lassen sich E-Mail-Adresse bereits bei der Datenerfassung auf
Plausibilität im Sinne syntaktischer Korrektheit der Werte prüfen.
Um diese auf E-Mail-Adressen zugeschnittene Datentypdefinition auch
an anderer Stelle wiederverwenden zu können, ist im Informationsmodell
ein allgemein für E-Mail-Adressen verwendbarer benutzerdefinierter
Datentyp bzw. Typ-Alias mit dem Bezeichner T_EMAILADRESSE
definiert.
Eine alternative Modellierungsmöglichkeit, die in Y.A.S. aber noch
nicht realisiert ist, bestände in der Verwendung eines eingebauten
Datentyps für E-Mail-Adressen, der in Anwendungen mit spezifischen
Funktionen verknüpft sein könnte, wie z. B. dem Erzeugen
einer neuen E-Mail bei Anklicken einer E-Mail-Adresse oder beim Aufruf
eines entsprechenden Kontextmenübefehls.
Das Attribut Geburtsdatum enthält das Geburtsdatum des
Entleihers als einfache Zeichenkette. Auch hier wird bzgl. des
Attributtyps auf die separate Typdefinition T_DATUM
verwiesen, die per Formatdefinition regelt, wie im Allgemeinen eine
Datumsangabe auszusehen hat.
Als alternative Modellierungsmöglichkeiten kommt entweder die
Verwendung eines benutzerdefinierten Strukturtyps mit einer
Aufschlüsselung der elementaren Datums-Bestandteile (Jahr, Monat,
Tag) oder die Verwendung eines eingebauten Datentyps für
Datumsangaben in Frage. Beides ist in Y.A.S. noch nicht realisiert.
Das Attribut Geschlecht gibt an, ob ein Entleiher
weiblichen oder männlichen Geschlechts ist. Zu diesem Zweck wird
in der Attributdefinition ein benutzerdefinierter anonymer
Aufzählungstyp mit den Werten MAENNLICH und
WEIBLICH vereinbart.
Alternativ könnte im Modell auch ein benannter Aufzählungstyp
T_GESCHLECHT mit den beiden Werten definiert und in der Attributdefinition
referenziert werden. Dies würde eine Wiederverwendung des
Aufzählungstyps an anderer Stelle im Modell ermöglichen.
Als weitere Modellierungsmöglichkeit käme aufgrund des
auf zwei Werte beschränkten Wertebereichs auch eine Repräsentation
als Attribut mit boolschem Datentyp in Frage.
Nachteilig wäre dabei allerdings, dass dann die Bedeutung der Werte
true und false explizit in der
Attributdokumentation festzulegen und entsprechend von allen
Programmen und Anwendern zu beachten wäre. Oder für das
Attribut müsste ein passender Name gewählt werden, z. B.
"istMaennlich".
Die Verwendung eines zweiwertigen Aufzählungstyps hat
gegenüber einem boolschen Typ den Vorteil,
dass eine spätere Erweiterung um zusätzliche Werte in der Regel
ohne Probleme machbar ist.
Das Attribut Lieblingsautoren enthält für jeden
Entleiher eine Liste mit den Namen seiner Lieblingsautoren.
Die einzelnen Namen der Lieblingsautoren werden als einfache Zeichenketten
dargestellt.
Die Anordnung (Reihenfolge) der Namen in der Zeichenkette kann vom Benutzer
frei manipuliert werden und soll hier nach absteigender Vorliebe erfolgen,
d. h. der am meisten favorisierte Autor steht in der Liste zu oberst.
In jeder solchen Liste sollte ein Autor höchsten einmal mit seinem
Namen eingetragen sein. Diese Beschräkung kann mit Y.A.S. im
Informationsmodell derzeit aber noch nicht spezifiziert werden.
Als alternative Modellierungsmöglichkeit böte sich eine
Repräsentation als Menge von Einträgen an, wenn die Anordnung
der Einträge nicht relevant wäre.
Für den Fall, dass die Autoren im Informationsmodell als eigene
Klasse repräsentiert wären, könnten die Listen- bzw.
Mengeneinträge auch direkte Referenzen auf die Instanzen dieser
Klasse sein. Allerdings brächte eine solche Modellierung die
Randbedingung mit sich, dass bei Entleihern nur die Lieblingsautoren
angegeben werden können, die als Autoren bereits durch eigene
Instanzen in der Datensammlung repräsentiert sind.
Das Attribut Nachname enthält den Nachnamen des
Entleihers als einfache Zeichenkette. Im Hinblick auf die
Bedeutung von Attributen und mögliche Modellierungsalternativen
sei am Beispiel des Nachnamens kurz angedeutet, dass sich
Attribute und insbesondere Namen, die sich vordergründig zur
Identifizierung von Objekten des Gegenstandsbereichs eignen,
bei nährer Betrachtung als über die Zeit veränderliche
Angaben herausstellen können. So kann der Nachnamen einer
Person sich z. B. bei Heirat, Scheidung und zukünftig ggf. auch
mit Erlangen der Volljährigkeit ändern.
Falls also in einer Datensammlung eine Zuordnung verschiedener Objekte
über den Wert von Namensattributen erfolgt, ist für die
Modellierung zu klären, ob nur aktuelle und konsistente
Werte verarbeitet bzw. für Anfragen genutzt werden oder ob auch
historische Werte ggf. sogar mit den entsprechenden
Gütigkeitszeiträumen einzubeziehen sind.
Die Referenzierung von Objekten über eine rein datentechnische und
nicht fachlich definierte Objektidentität stellt eine Alternative
zur Referenzierung von Objekten mittels fachlicher Attribute dar.
Sie ist gegenüber der geschilderten Problematik unempfindlich.
Sie garantiert dabei auch die Eindeutigkeit von Referenzen. Allerdings
funktioniert diese Technik nur bei Objekten, die in der Datensammlung
als Instanzen repräsentiert sind.
Dies ist jedoch nicht in jedem Fall gewährleistet, z. B. weil die
dazu erforderliche Datenerfassung nicht praktikabel ist.
Die Attribute Telefonnummer und
Telefonnummer_mobil enthalten die Festnetz-Telefonnummer
und die Mobilfunk-Telefonnummer des Entleihers als einfache Zeichenkette.
Auch hier wird bzgl. des
Attributtyps auf die separate Typdefinition T_TELEFONNUMMER
verwiesen, die per Formatdefinition regelt, wie im Allgemeinen die Angabe einer
Telefonnummer auszusehen hat.
Als alternative Modellierungsmöglichkeiten kommt entweder die
Verwendung eines benutzerdefinierten Strukturtyps mit einer
Aufschlüsselung der elementaren Telefonnummern-Bestandteile
(Ländesvorwahl, Regional-Vorwahl, Teilnehmeranschlussnummer)
oder die Verwendung eines eingebauten Datentyps für
Telefonnummern (evtl. sinnvoll für computergestützte
Telefon- bzw. Fax-Anwendungen) in Frage. Beides ist in Y.A.S. noch nicht
realisiert.
Das Attribut vertrauenswuerdig
dient als Beispiel eines Attributes mit boolschem Datentyp.
Attribute dieses Datentyps eignen sich besonders zur Repräsentation von
Eigenschaften eines Objektes, die entweder zutreffen oder nicht zutreffen.
Im vorliegenden Beispiel könnte es um die Eigenschaft gehen, ob an
einen potenziellen Entleiher z. B. wertvolle oder nicht mehr
wiederbeschaffbare Medieneinheiten ausgeliehen werden dürfen.
Das Attribut Vorname enthält den oder die Vornamen des
Entleihers als einfache Zeichenkette. Alternativ könnte in einem
Informationsmodell auch die Repräsentation einer Liste von
einzelnen Vornamen vorgesehen werden, wenn hierdurch z. B. bestimmte
Auswertung erleichtert würden.

Das Attribut RueckgabeBis enthält zu einer Medienleihe
(repräsentiert durch die Instanzbeziehung zwischen entliehener
Medieneinheit und dem zugeordneten Entleiher) das Datum, bis zu dem die
entliehene Medieneinheit durch den Entleiher zurückzugeben ist.
Für die Spezifizierung der zum Teil komplexen Attributwerte werden im Informationsmodell "Medienverwaltung" eine Reihe benutzerdefinierter Datentypen verwendet. Sie dienen der einfachen Wiederverwendung komplexer Datentypdefinitionen und verbessern zudem die Lesbarkeit und Wartbarkeit des Informationsmodells.
An dieser Stelle wird auf eine detaillierte Angabe und Erläuterung der benutzerdefinierten Datentypen verzichtet. Das folgende Klassendiagramm zeigt eine Übersicht der im Informationsmodell enthaltenen benutzerdefinierten Datentypen.

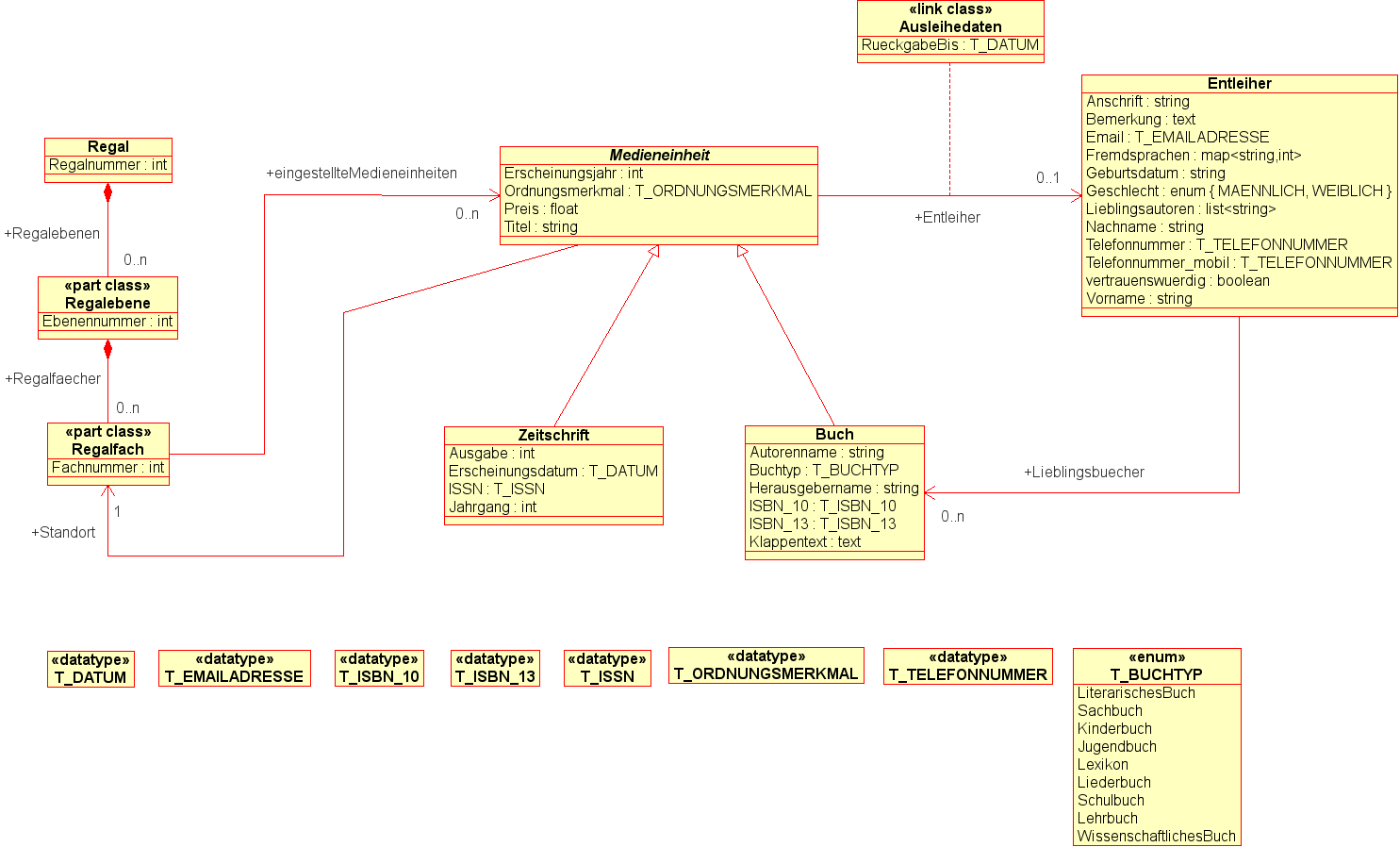
Wenn wir alle Klassendiagramme der vorherigen Abschnitte zu einem einzigen Klassendiagramm zusammenfassen, so ergibt sich die nachfolgend abgebildete Gesamtsicht auf das Informationsmodell "Medienverwaltung".
Die im Informationsmodell verwendeten Namen für Klassen, Attribute und benutzerdefinierte Datentypen stellen technische Bezeichner dar. Ihre Wahl unterliegt gewissen syntaktischen Restriktionen bzgl. der Menge verwendbarer Zeichen und der geforderten Verschiedenheit von reservierten Bezeichnern (analog zu Programmiersprachen). Unter realen Projektbedingung sind zusätzlich ggf. organisatorisch motivierte Benennungsregeln einzuhalten. Dies kann dazu führen, dass die technischen Bezeichner nicht mehr unmittelbar als Anzeigenamen für einen durchschnittlichen, mit dem zugrundeliegenden Gegenstandsbereich vertrauten Benutzer geeignet sind. Um in solchen Fällen unkomplizierte Abhilfe zu schaffen, erlaubt es Y.A.S., im Informationsmodell zu fast allen benannten Modellkonstrukten explizite Anzeigenamen zu definieren. Diese Anzeigenamen werden dann an der Benutzerschnittstelle insb. beim Erfassen und Anzeigen von Daten anstelle der technischen Bezeichner angezeigt werden. Hauptanwendungsfälle hierfür sind die korrekte Anzeige von Umlauten und die Vergabe besser lesbarer oder verständlicherer Anzeigenamen. Die Anzeige des Klassennamens in der Pluralform ist dagegen kaum üblich, aber abhängig vom Benutzerkreis und von der Akzeptanz der Bedienoberfläche ggf. diskussionswürdig.
Die nachfolgende Tabelle führt die Klassen und Attribute mit abweichendem Anzeigenamen auf.
| Klasse | Attribut | Anzeigename | Grund für abweichenden Anzeigenamen |
|---|---|---|---|
Medieneinheit |
Medieneinheiten | Anzeige des Klassennamens in der Pluralform | |
Buch |
Bücher | Anzeige des Klassennamens in der Pluralform | |
ISBN_10 |
ISBN (alt) | verständlichere Bezeichnung | |
ISBN_13 |
ISBN (neu) | verständlichere Bezeichnung | |
Zeitschrift |
Zeitschriften | Anzeige des Klassennamens in der Pluralform | |
Regalebene |
|||
Regalfaecher |
Regalfächer | korrekte Anzeige des Umlauts | |
Regalfach |
Regalfächer | Anzeige des Klassennamens in der Pluralform | |
Entleiher |
|||
Lieblingsbuecher |
Lieblingsbücher | korrekte Anzeige des Umlauts | |
vertrauenswuerdig |
vertrauenswürdig | korrekte Anzeige des Umlauts |
Desweiteren können wir im Informationsmodell zu jeder konkreten, vom Benutzer instanzierbaren Klasse zwei optionale Herleitungsregeln hinterlegen, die die Bildung von Anzeigenamen und Sortierkriterien für Instanzen der entsprechenden Klasse regeln. Allgemein ist es ratsam, zu jeder instanzierbaren Klasse zumindest die Regel für die Bildung fachlich aussagekräftiger und unterscheidbarer Anzeigenamen für Instanzen anzugeben. Eignen sich die Anzeigenamen für Instanzen auch direkt als Kriterium zur sortierten Anzeige der Instanzen, so kann auf die Angabe eines separaten Sortierkriteriums verzichtet werden.
Zu den Klassen der Informationsmodells "Medienverwaltung" sind folgende Bildungsregeln hinterlegt:
| Eigenschaft | Bildungsregel | Erläuterung |
|---|---|---|
| Anzeigename für Instanzen |
(Autorenname?:"???") |
Der Anzeigename einer Instanz der Klasse Buch wird gebildet
durch Aneinanderreichung des Autorennamens, der konstanten Zeichenkette
": " und des Buchtitels. Als Autorenname und Buchtitel
werden die aktuellen Werte der Attribute Autorenname
und Titel der jeweiligen Instanz verwendet. Sollte
einer der beiden Attributwerte undefiniert (null) sein,
so wird jeweils ersatzweise die konstante Zeichenkette "???"
anstelle des undefinierten Attributwertes eingesetzt.Beispiel: "Udo Neumann: Lizenz zum Klettern V3"
|
| Sortierkriterium für Instanzen |
_class._name |
Das Sortierkriterium zu einer Instanz der Klasse Buch wird
gebildet durch Aneinanderreichung des Klassennamens, eines Leerzeichens,
des Autorennamens, der konstanten Zeichenkette ": "
und des Buchtitels.
Der vorangestellte Klassenname dient dazu, dass Instanzen derselben Klasse
bei einer klassenübergreifenden Sortierung direkt aufeinander
folgen.Beispiel: "Buch Udo Neumann: Lizenz zum Klettern V3"
|
| Eigenschaft | Bildungsregel | Erläuterung |
|---|---|---|
| Anzeigename für Instanzen |
(Titel?:"???") |
Der Anzeigename einer Instanz der Klasse Buch wird gebildet durch
Aneinanderreichung des Autorennamens, der konstanten Zeichenkette
": " und des Buchtitels. Als Autorenname und Buchtitel
werden die aktuellen Werte der Attribute Autorenname
und Titel der jeweiligen Instanz verwendet. Sollte
einer der beiden Attributwerte undefiniert (null) sein,
so wird jeweils ersatzweise die konstante Zeichenkette "???"
anstelle des undefinierten Attributwertes eingesetzt.Beispiel: "Panorama 2010/4"
|
| Sortierkriterium für Instanzen |
_class._name |
Das Sortierkriterium zu einer Instanz der Klasse Zeitschrift
wird gebildet durch Aneinanderreichung des Klassennamens, eines Leerzeichens,
des Titels, eines weiteren Leerzeichens, des Erscheinungsjahres,
eines Schrägstriches und der Ausgabenummer.
Der vorangestellte Klassenname dient dazu, dass Instanzen derselben Klasse
bei einer klassenübergreifenden Sortierung direkt aufeinander
folgen.Beispiel: "Zeitschrift Panorama 2010/4"
|
| Eigenschaft | Bildungsregel | Erläuterung |
|---|---|---|
| Anzeigename für Instanzen |
"Regal " |
Der Anzeigename einer Instanz der Klasse Regal wird gebildet
durch Aneinanderreichung der konstanten Zeichenkette
"Regalebene " und Regalnummer. Als Regalnummer wird der
aktuelle Wert des Attributes Regalnummer der jeweiligen
Instanz verwendet.Beispiel: "Regal 4"
|
| Sortierkriterium für Instanzen |
_class._name |
Das Sortierkriterium zu einer Instanz der Klasse Regal
wird gebildet durch Aneinanderreichung des Klassennamens, eines Leerzeichens
und der mit führenden Nullen dreistellig dezimal angegebenen
Regalnummer.
Der vorangestellte Klassenname dient dazu, dass Instanzen derselben Klasse
bei einer klassenübergreifenden Sortierung direkt aufeinander
folgen.Beispiel: "Regal 004"
|
| Eigenschaft | Bildungsregel | Erläuterung |
|---|---|---|
| Anzeigename für Instanzen |
"Regalebene " |
Der Anzeigename einer Instanz der Klasse Regalebene wird
gebildet durch Aneinanderreichung der konstanten Zeichenkette
"Regalebene ", der Regalnummer des zugehörigen Regals,
eines Schrägstrichs und der Ebenennummer der zugehörigen
Regalebene.
Als Regalnummer wird der aktuelle Wert des Attributes
Regalnummer der jeweiligen besitzenden Instanz der Klasse
Regal verwendet, als Ebenennummer der aktuelle Wert des
Attributes Ebenehnummer der jeweiligen Instanz der Klasse
Regalebene.Beispiel: "Regalebene 4/7"
|
| Sortierkriterium für Instanzen |
_class._name |
Das Sortierkriterium zu einer Instanz der Klasse Regalebene
wird gebildet durch Aneinanderreichung des Klassennamens, eines Leerzeichens,
der mit führenden Nullen dreistellig dezimal angegebenen Regalnummer,
eines Bindestrichs und der mit führenden Nullen zweistellig dezimal
angegebenen Ebenennummer.
Der vorangestellte Klassenname dient dazu, dass Instanzen derselben Klasse
bei einer klassenübergreifenden Sortierung direkt aufeinander
folgen.Beispiel: "Regalebene 004-07"
|
| Eigenschaft | Bildungsregel | Erläuterung |
|---|---|---|
| Anzeigename für Instanzen |
"Fach " |
Der Anzeigename einer Instanz der Klasse Regalfach wird
gebildet durch Aneinanderreichung der konstanten Zeichenkette
"Fach "", der Regalnummer des zugehörigen Regals,
eines Schrägstrichs, der Ebenennummer der zugehörigen Regalebene,
eines weiteren Schrägstrichs und der Fachnummer des Regalfachs.
Als Regalnummer und Ebenennummer werden die aktuellen Werte der Attribute
Regalnummer und Ebenennummer der jeweiligen
mittelbaren bzw. unmittelbaren besitzenden Instanzen der Klasse
Regal bzw. Regalebene verwendet, als Fachnummer
der aktuelle Wert des Attributes Fachnummer der jeweiligen
Instanz der Klasse Regalfach.Beispiel: "Fach 4/7/11"
|
| Sortierkriterium für Instanzen |
_class._name |
Das Sortierkriterium zu einer Instanz der Klasse Regalfach
wird gebildet durch Aneinanderreichung des Klassennamens, eines Leerzeichens,
der mit führenden Nullen dreistellig dezimal angegebenen Regalnummer,
eines Bindestrichs, der mit führenden Nullen zweistellig dezimal
angegebenen Ebenennummer, eines weiteren Bindestrichs und der mit
führenden Nullen zweistellig dezimal angegebenen Fachnummer.
Der vorangestellte Klassenname dient dazu, dass Instanzen derselben Klasse
bei einer klassenübergreifenden Sortierung direkt aufeinander
folgen.Beispiel: "Fach 004-07-11"
|
| Eigenschaft | Bildungsregel | Erläuterung |
|---|---|---|
| Anzeigename für Instanzen |
((Vorname!=null) |
Der Anzeigename einer Instanz der Klasse Entleiher wird gebildet durch
Aneinanderreichung des Vornamens, eines Leerzeichens und des
Nachnamens des Entleihers. Als Vorname und Nachname
werden die aktuellen Werte der Attribute Vorname
und Nachname der jeweiligen Instanz verwendet. Sollte
der Wert des Attributs Vorname undefiniert (null)
sein, so entfällt der Vorname und das Leerzeichen im Anzeigenamen.Beispiel: "Barbara Bücherwurm"
|
| Sortierkriterium für Instanzen |
Da kein Sortierkriterium angegeben ist, verwendet Y.A.S. den Anzeigenamen als Sortierkriterium. |
Für die werkzeuggestützte Erstellung von Datenmodellen kommen häufig gängige Datenmodellierungswerkzeuge zum Einsatz. In der Regel erlauben sie neben einer maskengeführten Definition der Modellelemente auch die Erstellung graphischer Repräsentationen in Form entsprechender Diagramme. Für die Visualisierung objektorientierter Datenmodelle bieten sich Klassendiagramme an, die Bestandteil der Unified Modelling Langugage (UML) sind. Der Objektdatenmodelleditor in Y.A.S. bietet derzeit keine Funktion zur graphischen Modellierung. Ersatzweise verwenden wir das UML-Modellierungswerkzeug Umbrello, um zu unserem Informationsmodell ein entsprechendes Klassendiagramm zu erstellen.
Umbrello ist von seinem Haupteinsatzbereich, der statischen Klassenmodellierung im Rahmen des objektorientierten Programmentwurfs, auf die Code-Generierung für objektorientierte Programmiersprachen ausgerichtet. Sein Metamodell deckt entsprechend nicht alle Details des Metamodells von Y.A.S. ab. Es kann vom Benutzer auch nicht per Konfiguration erweitert werden, wie dies bei anderen, in der Regel kostenpflichtigen UML-Modellierungswerkzeugen üblich ist. Folglich wird Umbrello hier nur zur Erstellung von Klassendiagrammen verwendet, um die mit Y.A.S. definierten Informationsmodelle zu visualisieren. Auf eine tooltechnische Anbindungen von Y.A.S. an Umbrello bzw. umgekehrt wurde aus besagtem Grund verzichtet.
Angaben aus dem Informationsmodell, die im Metamodell von Umbrello
nicht abgebildet werden können, fehlen im erstellten
Klassendiagramm oder sind nur unzureichend repräsentiert.
Dies betrifft insbesondere die Angabe des Datentyps bei Attributen.
Hier wird nur der Grundtyp (z. B. boolean,
float, int, string, ...) ausgewiesen,
nicht jedoch die dazu spezifizierten Restriktionen, wie z. B. die
Zulässigkeit von Null-Werten (bei allen Typen), Wertebereichsgrenzen
(bei numerischen Typen), die numerische Repräsentation
der Werte von Aufzählungstypen oder die Beschränkung des
Zeichenvorrats, der Länge oder der zulässigen Zeichenfolgen
(bei Zeichenkettentypen).
Der besseren Verständlichkeit wegen sind mehrzeilige Zeichenketten
im Klassendiagramm mit der Typangabe text ausgewiesen,
während sie im Informationsmodell von Y.A.S. den Datentyp
string mit der zusätzlichen Typ-Attributierung
multiline tragen.
Ebenfalls nicht angezeigt wird im Klassendiagramm die gewählte
Klassenart bei gewöhlichen Klassen, um die Übersichtlichkeit
zu erhöhen.
Bei Teil-Klassen und Verbindungs-Klassen erfolgt die Anzeige
gemäß UML über den Namen des Stereotyps
(part class bzw. link class).
Benutzerdefinierte Typdefinitionen (Typ-Aliase) und Aufzählungstypen
werden im Klassendiagramm ohne graphische Verbindung zu den
Verwendungsstellen dargestellt.
Die entsprechenden Zusammenhänge erschließen sich
dem Betrachter jedoch anhand der bei den Attributen angegebenen Typnamen.
Dies wird organisatorisch dadurch unterstützt, dass die Namen
benutzerdefinierter Datentypen einheitlich komplett in Großbuchstaben
geschrieben sind und mit dem Präfix "T_" beginnen..
Die Darstellung von Typdefinitionen und
Aufzählungstypen erfolgt mit den Stereotyp-Namen
datatype und enum.
Containertypen wie list<...>,
map<...> und set<...>
werden nur bei direkter Verwendung für
nicht referenzielle Attribute angezeigt.
Referenzielle Attributen sind graphisch stets durch entsprechende
Kanten zwischen Ausgangs- und Zielklasse repräsentiert.
Hier deutet lediglich die Angabe einer Kardinalität
(z. B.: 0..n) auf die Verwendung eines Containertyps hin,
der im Diagramm aber nicht dargestellt wird.
Y.A.S. erlaubt die lokale Definition benutzerdefinierter Datentypen
innerhalb von Klassen. Das UML-Modellierungswerkzeug Umbrello
unterstützt jedoch keine lokalen Typdefinitionen innerhalb von
Klassen, so dass die Lokalität von Typdefinitionen
nicht im Klassendiagramm visualisiert wird. Im Informationsmodell
"Medienverwaltung" betrifft dies den Datentyp bzw.
Typ-Alias T_ORDNUNGSMERKMAL, der lokal in der Klasse
Medieneinheit definiert ist.